Efficient Forwarding Anomaly Detection in Software-Defined Networks
affliation and publication
- author: Qi Li, Yunpeng Liu, Zhuotao Liu, Peng Zhang, Chunhui Pang
- publication: TPDS
- abs 本篇是FADE的翻篇版, 对FADE加强了然后发了个好的,主要思想:收集网络的rule path,并找到可以通过所有这些path的最小流,并用专用rule覆盖指定的rule path中的一些rule,再生成探针包并对专用rule统计从而得到当前是否有异常.
Introduction
它将大数据背景引入本文
Related Work
Problem Statement
Background
SDN本身的不足,问题的重要性,问题的广泛性

An Inductory Example
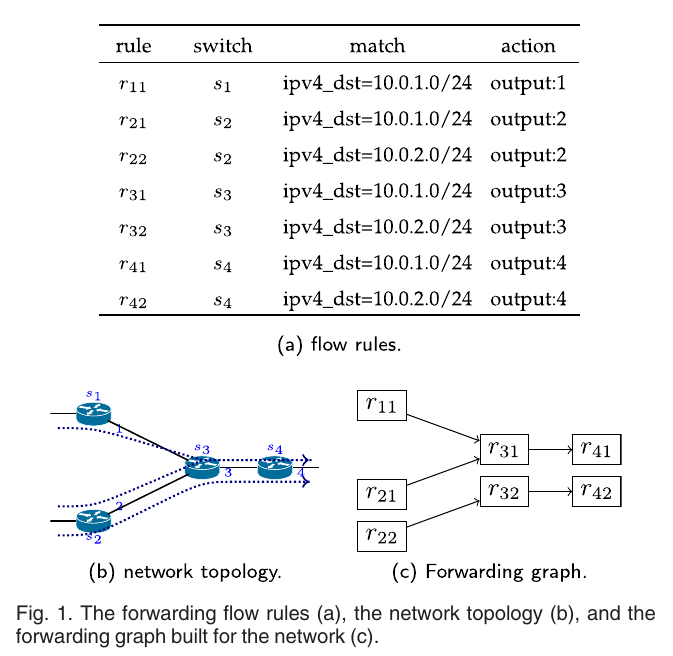
- 说明什么是rule path: 包在网络中所有匹配的规则序列记为rule path
- 攻击类型
- Traffic hijacking: 将流丢弃,重定向到错误的path中,并不会返回原来的rule path
- traffic interception: 流被导到错path上,但还会回到正确的path.
FADE设计
Design Overview
 由四个组件组成
由四个组件组成
- Flow selection model: 生成网络将会图,选择能够覆盖所有rule paths的最小flow 集
- 决定生成的rule数
- 下发专用流表
- 统计并检测异常
Flow Selection
- 构建flow rules graph(利用HSA[39])
- 利用算法1选择时最小流集:对每个egress rule, 反向深度找rule path的每个rule,直到ingress gule,如此找到所有的rule path.

Probe Selection
对于给定的流,对它经过的rule path中选择一些rule,这些rule称为probe.
rule path的第一个rule和最后一个rule一定要选择; 对于其他的rule选择,则通过一个概率计算的方式来选择.
过程略,因第链路通常长度不会超过32,最终最优选择结果如表2:

Rule Generation
下发的rule分为两种记为\(\mathcal{R}_1, \mathcal{R}_2\). \(\mathcal{R}_1\)覆盖第一个probe,负责匹配包并向其插入一个可识别的label. \(\mathcal{R}_2\)覆盖其他的probe,负责对插入label的包进行计数.
这两个规则也插入数据平面时要注意时间, 在\(\mathcal{R}_\)生效之前\(\mathcal{R}_2\)应该已经生效 \(\mathcal{R}_1\)失效前\(\mathcal{R}_2\)应该继续存在一段时间记\(i_1,i_2\)分别为它们的下发时间,\(t_1,t_2\)分别为它们的有效时间, 作者对下发时间和有效时间作了些约束,可见原语言
Anomaly Identification and Location
对于第一个rule的匹配包数计为\(p_1\),假设共有k个rule, 若出现,\(p_1 \neq p_k\),在\(s_1,s_{k}\)之间发生了hijack攻击.则可定位有问题的交换机发生在所有不相等中下标最小的交换机与\(s_1\)之间 当\(p_1=p_k\)时,此时仍可发生interception攻击,因此需要进一步判定:对于\(2 \le u \le v \le k-1\),\(i \in [u,v], j \notin [u,v], j \in (1,k)\),若\(p_i \neq p_j\), 则可定位在\(s_{u-1},s_v\)之间发生了异常这部分算法如算法2:

iFADE Design
对FADE改进从而降低rule数量
Rule computation under Flow Aggregation
iFADE同样由flow selection, probe selection, rule generation, anomaly identification组成.
Flow Selection
- 在同一个switch中,具有相同action的所有的egress rule组成一个rule category,
- 这个category执行DFT向前查找其上行rule,若它们的上行rule行为不同(这里我理解为来自不同的switch),则这个category分割,
- 直到找到ingress rule为止.
过程见算法3

Dedicated Rule Generation
这部分讲怎么成生\(R_1,R_2\),具体的没怎么看懂,大概意思是\(R_1\)可能对多个流添加相同的label.
Anomaly Identification
Scheduling Detection
又来了个看不懂的操作
Implementation
- floodlight 实现
- 组成:
- storage module
- rule graph module
- anomaly detection module
- 源码 在这里
Evaluation
Experiment Setup
使用了两个工具:
- iperf
- Cbench http://ctuning.org/wiki/index.php?title=CTools:CBench
- ovs-ofctl
将配置信息放在表6中:

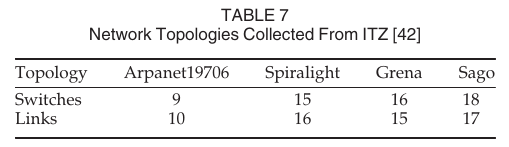
将实验中使用的不同拓扑信息放在表7中:
Detection Accuracy and Efficiency
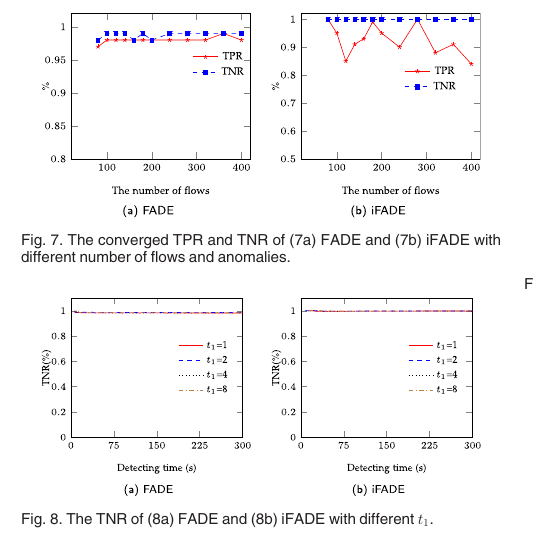
基本设定: 4个现实网络, 每个网络拓扑生成200个网络流, 4个异常流规则, 每个流统计2秒, 每个实验进行5分钟. 结果见5a和5b. 1. TPR和TNR都最终收敛到1;2. FADE需要几秒定位第一个异常, 需要十几秒定位所有的异常. 图6a和6b是对iFADE的实验结果, 作者对不同的结果原因进行了分析(锅都甩给了OVS).
对不同数量网络流以及不同数量异常流的情形进行实验, 流的设定如表8所示. 实验结果的TPR和TNR见图7a, 7b所示. 结论: 1. FADE很健壮, 流的数量对它的影响较小. 2. iFADE不大好的原因怪在OVS的统计不准上. 对流的统计时间影响评估, 分别测量统计时间为1,2,4,8的TPR和TNR, 结果在图5c和图6c中. 结论: 1. FADE很健壮, 但统计时间越长, 检测延迟也越长;2. 由于OVS的统计不准, 统计时间琥长, iFADE的结果就越好. 因此要均衡检测准确率与效率没介绍图8a与图8b是什么鬼.
FADE和iFADE在不同拓扑上,检测的TPR,TNR随检测时间的变化,感觉它这个检测时间还挺长,几十秒,图5,6
检测当存在大量的网络流和大量的异常rule时,TPR和TNR的变化,图7.
评估TNR随\(R_1\)的存在时间的变化,如图8,TPR的变化如图5,6的c

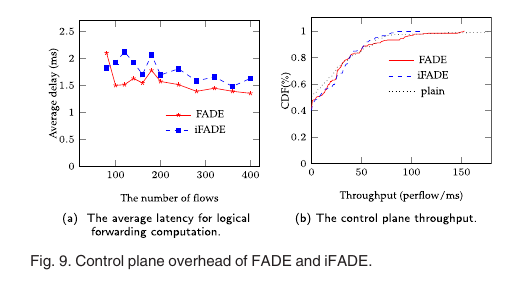
The Control Plane Overhead
latency:平均延迟随网络流数增长的变化见图9a,这个延迟指的是重构交付图,重选择probes,重生成特定规则的时间. PacketIn throughput: 比较FADE和iFADE运行时packetIn的产生量,图9b
The Data Plane Overhead
专用规则数和数据平面吞吐量随网络流数的变化.图10

Effectiveness of Heuristics in Large-scale Topology
对的测试,比较他的解法和最优解的区别

Experimental Comparison With SPHINX
与其他算法的比较

如果这篇文章帮到了你, 那就赞助我一瓶水吧, 这可以让我有动力去写更多的文章
Sponsor