EPIC: Every packet is checked in the data plane of a path-aware internet
简单介绍
这是一篇最近NSDI上路径验证相关的论文.看了好几遍但还是没进脑子,因此在此总结一遍.
路径构建
终端主机如何根据AS的信息构造包的传输: 终端主机\(H_S\)首先从路径服务器中找到路径path(文中有个beacon的词,翻译为信标,估计跟路径差不多), 并将路径嵌入到数据包中,如下:
\[PACKET := (PATH || VALHD || P) \tag{1}\]
\[PATH := (TS_{path} || SRC || DEST || HI_1 || … || HI_l) \]
\[VALHD := (ts_{pkt} || S_1 || V_1 || … || S_l || V_l || V_{SD})\]
其中P表示数据包的负载, \(SRC := (A_1 : H_S), DEST:=(A_l: H_D)\). VALHD中为验证数据包所需要的一些域, \(ts_{pkt}\)为时间戳, \(S_i\) 为每一跳的验证加密码. \(V_i\) (HVF)为由源填充的加密标签,用于让中间路径验证数据包.
术语 hop field 指由跳信息 HI, 段识别 S 和跳验证域组成的三元组. 术语packet origin为h同源,路径时间戳,数据包时间戳组成的三元组:
\[PO:=(SRC, TS_{path}, ts_{pkt})\]
TODO 文中的一些标记
TODO 全局对称密钥分布
每个AS怎么分配密钥的.
EPIC 协议
分为1-3级,安全性依次升高. 并使用0级作为最基础的方法.
L0: 路径授权
L0阶段使用静态消息验证码MAC作为跳验证HVF. 在路径探索阶段, AS A 首先计算跳验证器\(\sigma^{(0)}\)作为MAC. 当前跳验证器与前一跳验证器\(\sigma^{(0)’}\)的关系为(截断到\(l_{val}\)位):
\[\sigma_A ^{(0)} := MAC_{K_A}(TS_{path} || HI_A || \sigma^{(0)’})[0:l_{val}] \tag{5}\]
这个跳验证器直接用作HVF, 即\(V_i^{(0)} = \sigma_i^{(0)}\), 初始化时没有前一跳,因此式中就不包函\(\sigma^{(0)’}\).
数据包的创建与交付过程为:
源: HS 获得 path后, 按式(1) 构造包.
传输: 每一个\(A_i\), 它的边缘路由节点先检查HIi检查是否来自正确的接口并检查hop域是否过期,然后再重新计Vi并检查它是否与数据包头HVF中的相同。
L1: improved 路径授权
L0的不安全性分析: 假设每一跳的验证位长度为3字节, 则攻击者最多要发送 \(2^{24} \approx 1.6 \cdot 10^7\) 个数据包就可以找到这一跳的一个正确的MAC,这在一个Gb链路上大概要10s即可. 这种静态的MAC一旦被猜到后就可被利用来发送额外的数据包.
L1中将静态跳验证替换为 per-packet HVFs, 这样它就无法被其他数据包重用了. 这时跳验证器的计算公式为:
\[\sigma_A^{(1)}:=MAC_{K_A}(TS_{path}||HI_A||S^{(1)’}) \tag{6}\]
其中, \(S^{(1)’}\)为前一跳的段识别器, 通过截断跳验器来获得:
\[S^{(1)}:=\sigma^{(1)}[0:l_{set}] \tag{7}\]
跳验证器会被源主机用于计算每个数据包的HVF:
\[V_i^{(1)} :=MAC_{\sigma_i^{(1)}}(ts_{pkt}||SRC)[0:l_{val}] \tag{8}\]
HVF通过式(8)计算,这使得每个包的HVF都是不相同的。S首先根据式(7)和式(8)计算构造HVF。当中间路由节点接收到包时先和L0一样验首接口和过期时间,它首先用式(6)计算跳数authenticator,再用式(7)计算它自己的段识别,再使用式(8)计算HVF,将算得的结果与包中的对比相同则交付包。
这里与L0不同的: L0中 每个数据包的HVF都是\(\sigma\), 是相同的, 而这里的HVF在计算时使用了每个数据包的时间戳, 所以每个数据包验证时HVF都是不同的.
虽然每个HVF只能被一个包使用,但攻击者仍可利用它所知道的一些PVF或重用时间戳进行DoS攻击,但可以使用[29]中的方法解决这个问题。
L2: 授权
相较于L1添加了由中间路由验证数据包的源和目的机制. 提出了主机密钥机制,计算方法为:
主机密钥: \(K_i ^S:=K_{A_i \rightarrow A_1:H_S}\) 每一个中间AS \(A_i\)的额外密钥: \(K_{SD}:=K_{A_l:H_D \rightarrow A_1 : H_S}\)
上面这两个密钥可以被用于计算带有源验证的HVF:
\[V_i^{(2)}:=MAC_{K_i^S}(ts_{pkt}||SRC||\sigma_i)[0:l_{val}] \tag{10}\]
目的主机可授权数据包的源并对数据包的路径和负载的验证域:
\[V_{SD}^{(2)}:=MAC_{K_{SD}}(ts_{pkt}||PATH||P) \tag{11}\]
源需要获取所有host的key,在计算HVF时与L0和L1不同的是,它使用了主机key,见式(10),另外还计算了Vsd见式(11)。中间路由节点除要验证L1中验证的外,还需计算主机key并验证包头中的HVF是否与式(10)中的相符。目的主机获得Ksd并验证Vsd是否符合式(11)。
(这个L2相较于L1添加了源和目的验证, 本质上与L1区别不大,就是在验证域HVF的计算过程中添加了源和目的主机的key)
L3: 终端主机路径验证
相较于L2: 允许数据包的源和目的进行路径验证.
每个中间AS接收到数据包后都对数据包的HVF进行了修改,当目的接收到包后便可基于验证域内容进行验证. 定义(其实就是未截断的式(10)):
\[C_i := MAC_{K_i^S}(ts_{pkt}||SRC||\sigma_i) \tag{12}\]
我们可以将这个分成多块:
\[C_i^{[1]}:=C_i[0:l_{val}], C_i^{[2]}:=C_i[l_{val}:2l_{val}] \tag{13}\]
源为每个数据包的HVF设定:\(V_{i;0}^{(3)}:=C_i^{[1]}\).
当中间交换机\(A_i\)收到数据包后先计算\(C_i\),并验证HVF对不对,然后再更新HVF的验证域: \(V_{i;i}^{(3)}:=C_i^{[2]}\).
为使目的主机也能参与验证, 作者将最终值\(V_{i;l}^{(3)}\)放到目的验证域:
\[V_{SD}^{(3)}:=MAC_{K_{SD}}(ts_{pkt}||PATH||V_{1;l}^{(3)}||\cdots ||V_{l;l}^{(3)}||P) \tag{14}\]
L4:
在附录部分加了个L4.
安全性分析
basic and strong attacker models
-
basic-attacker model:
-
Strong-Attacker Model: 定义一个神喻函数\(\mathcal{O}^{(l)}\), 它可以从给定的PO和HI中产出有效的HVF \(V_i\)有段识别\(S_i\): \(\mathcal{O}(PO,HI_1,…,HI_l)=(V_1^{(l)},…,V_l^{(l)}, s_1^{(l)},…,S_l^{(l)}\) 攻击者可以查询这个神喻函数并学习到\(V_i,S_i\).(\(\sigma_i,V_{SD}\)不行). 这使得攻击者可以构造已有的数据包(无法构造不同的数据包). 这么作的攻击效果有限.

Low Risk of Forging Individual Packets
对前面攻击危害性不强一顿解释.
Path Authorization
P1: 路径授权: 数据包在网络中传输只会沿着被路径上的诚实AS授权的路径进行.
Freshness
P2: Freshness: 数据包被独一无二的识别, 无法被重放.
Packet and Source Authentication
P3: Packet authentication for \(H_D\): 目的主机与源对数据包的源,路径,负载达成一致.
P4: Source authenticaiton for router: 路径上的AS与源对packet origin达到一致.
TODO Path Validation
这个先不管了, 这些分析不知道到底有啥用.
实验部分
吞吐量:
图1:单核,不同负载尺寸下,源的吞吐量与路径长度的关系;
图7:不同的包负载尺寸,不同的核数时,源的性能(吞吐量,产量)
图8:单核,不同的包负载尺寸,不同的路径长度,源的处理时间.
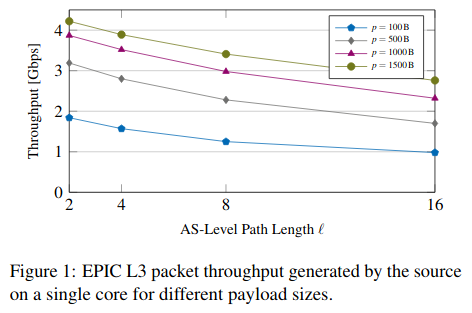
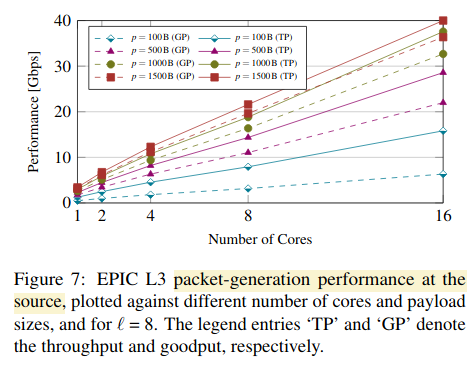
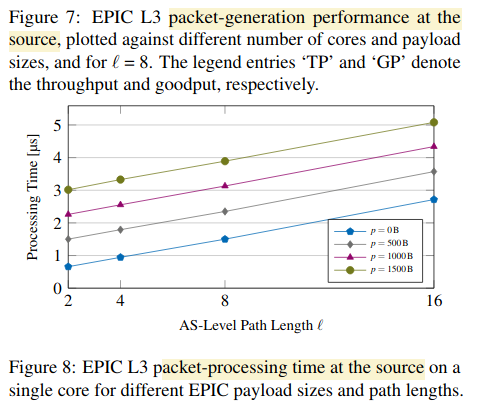
图2: 路径长度为8时,不同的核心数的交付性能,可见当负载尺寸>=500B时,4核,可以使40Gbps的链路饱和. 使用16核时可在负载尺寸为100B时使链路饱和.
图4:不同的交付任务,在不同的跳数情况下,路由的处理时间
图5: 在不同的跳数时,负载尺寸增加时路由的处理时间
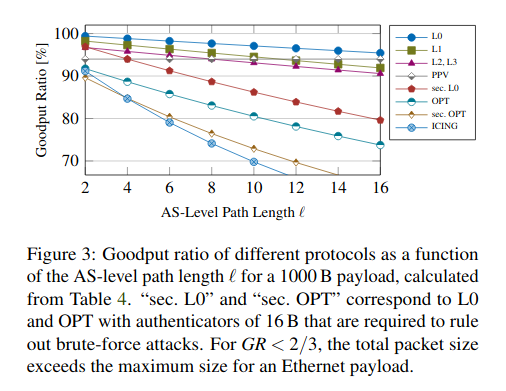
图6:交付性能随核数的变化(由图4,5知交付性能与跳数和尺寸无关).
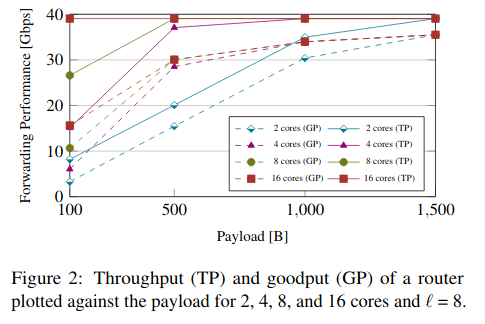

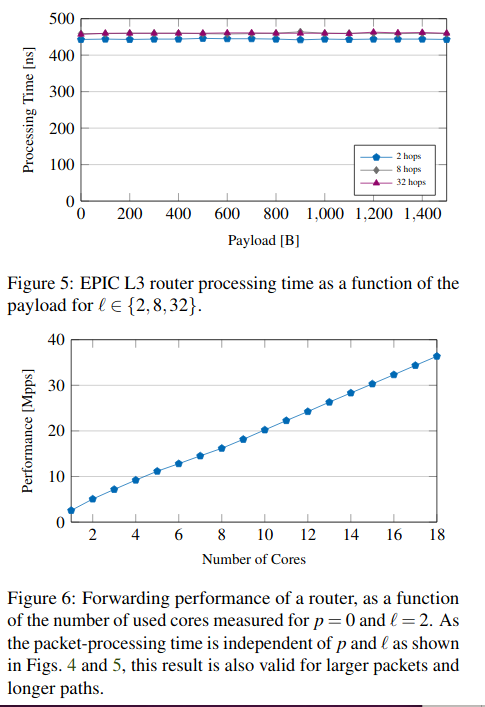
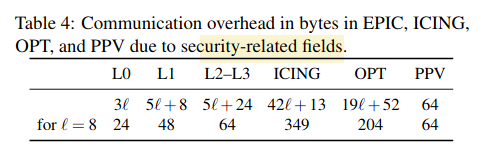
图3: 不同协议,不同的路径长度下,goodput ratio的变化;
表4: 不同协议 以及本方法不同等级时,所需要的额外不同头域大小.
如果这篇文章帮到了你, 那就赞助我一瓶水吧, 这可以让我有动力去写更多的文章
Sponsor